DEVOPS
Team isolation in Kubernetes: the four-layer stack that actually works
Rein Remmel
06. August, 2025

Sharing Kubernetes clusters between teams works fine when everyone knows how to keep their applications isolated and resources separated. But what if the development teams are not Kubernetes experts?
In a small organization it is possible for a dedicated employee or a SRE team to take the central expert role and manage everything Kubernetes and application deployment related. But this model doesn't scale when you want teams to be self-sufficient and avoid team bottlenecks or gatekeepers.
Entigo is a SRE service provider, and our job is to keep things under control. So far our team has successfully used the central gatekeeper model to protect production environments. It's been great at preventing the classic disasters: teams stepping on each other's toes, resource exhaustion, and production outages.
However, this is incredibly time-consuming manual labor. Every deployment request, every resource allocation, every troubleshooting session flowing through the central team isn’t scalable.
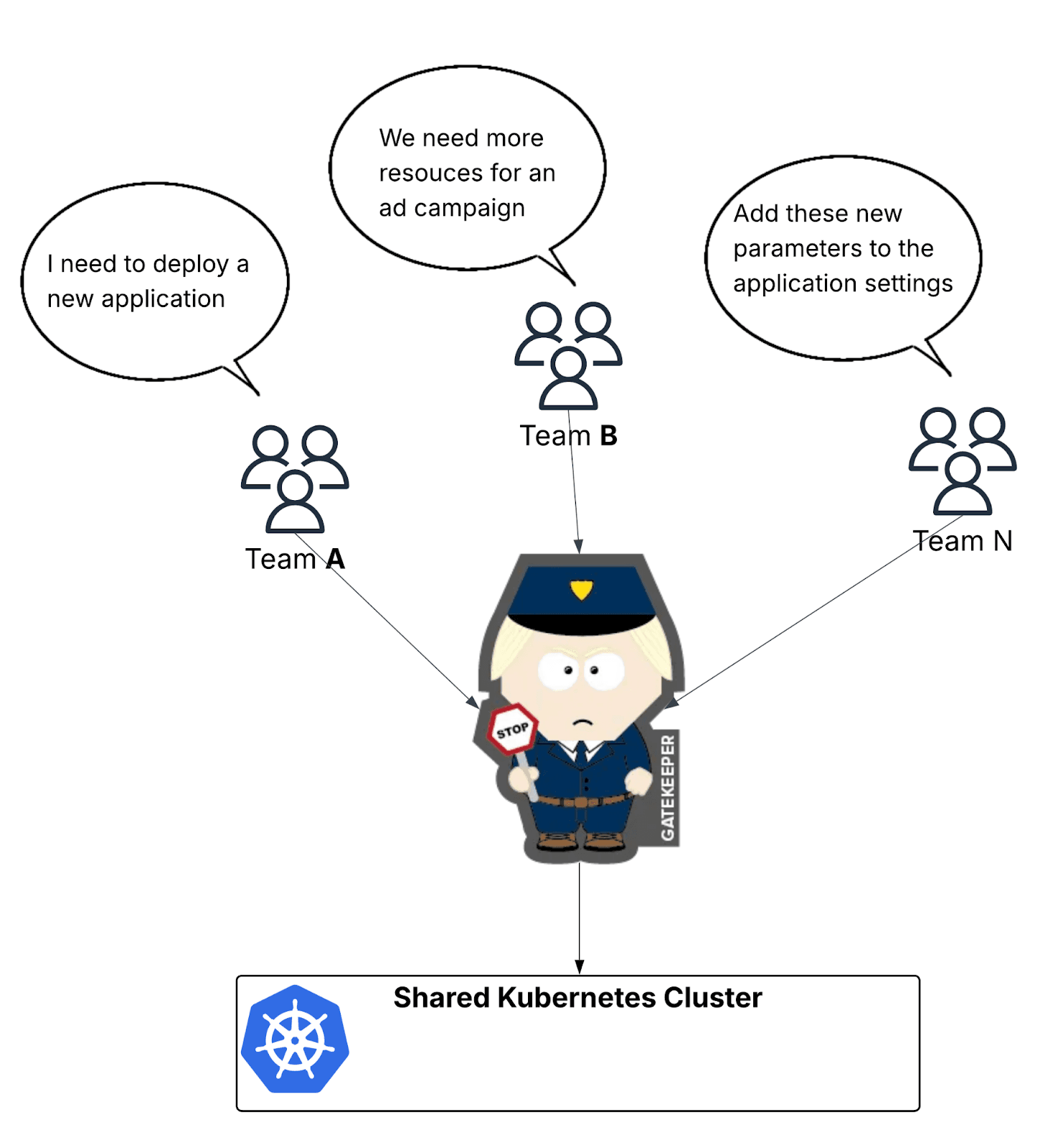
More importantly, this centralized model goes against everything we believe about team autonomy. Teams should be independent and able to serve themselves. They shouldn't need to file tickets and wait for SRE approval every time they want to deploy a feature or scale their application.
So we started looking for measures that would allow teams to access the cluster directly without requiring constant intervention.
Here's the four-layer isolation stack that finally made team self-service possible.
The problem: shared resources and the bottleneck
Kubernetes supports namespaces for logical isolation. Namespaces are a good building block for team isolation, but fall short when it comes to actual compute resource isolation.
Even if teams deploy to different namespaces their Pods may still be scheduled on the same worker node and be exposed to noisy neighbor risks. There are many disaster stories about an ETL job consuming all cluster memory, the monitoring pods that can't schedule because someone used all the quota, and cross-team resource exhaustion that brought down production.
To prevent these disasters our SRE services have offered constant manual oversight:
- Reviewing every deployment for resource conflicts
- Manually coordinating node assignments across teams
- Troubleshooting scheduling issues when teams don't understand Kubernetes resource allocation
- Managing resource quotas and adjusting them as team needs evolve
This model works well when you have a handful of teams and applications, but becomes expensive and does not scale when your company is in a growth phase and your product teams need to move fast.
The solution: four tools and the pursuit of autonomy
DevOps is all about team independence and platform engineering should be enabling it with self-service tools. Instead of trying to scale the gatekeeper role, we wanted to build on Kubernetes and AWS cloud capabilities to address risks and enable developer self-service. After testing different approaches across several implementations, we found four tools that, when combined, create something way more powerful than the sum of their parts:
- Namespaces - your basic Kubernetes room dividers, but with actual enforcement
- Karpenter - smart node provisioning that gives each team their own compute resource pool
- OPA Gatekeeper - the strict parent that makes sure pods go where they're supposed to
- ArgoCD - GitOps magic that keeps deployments sane and traceable
The key insight we had after implementing this pattern multiple times? None of these tools are particularly special on their own, but together they cover each other's weaknesses and create good enough isolation.
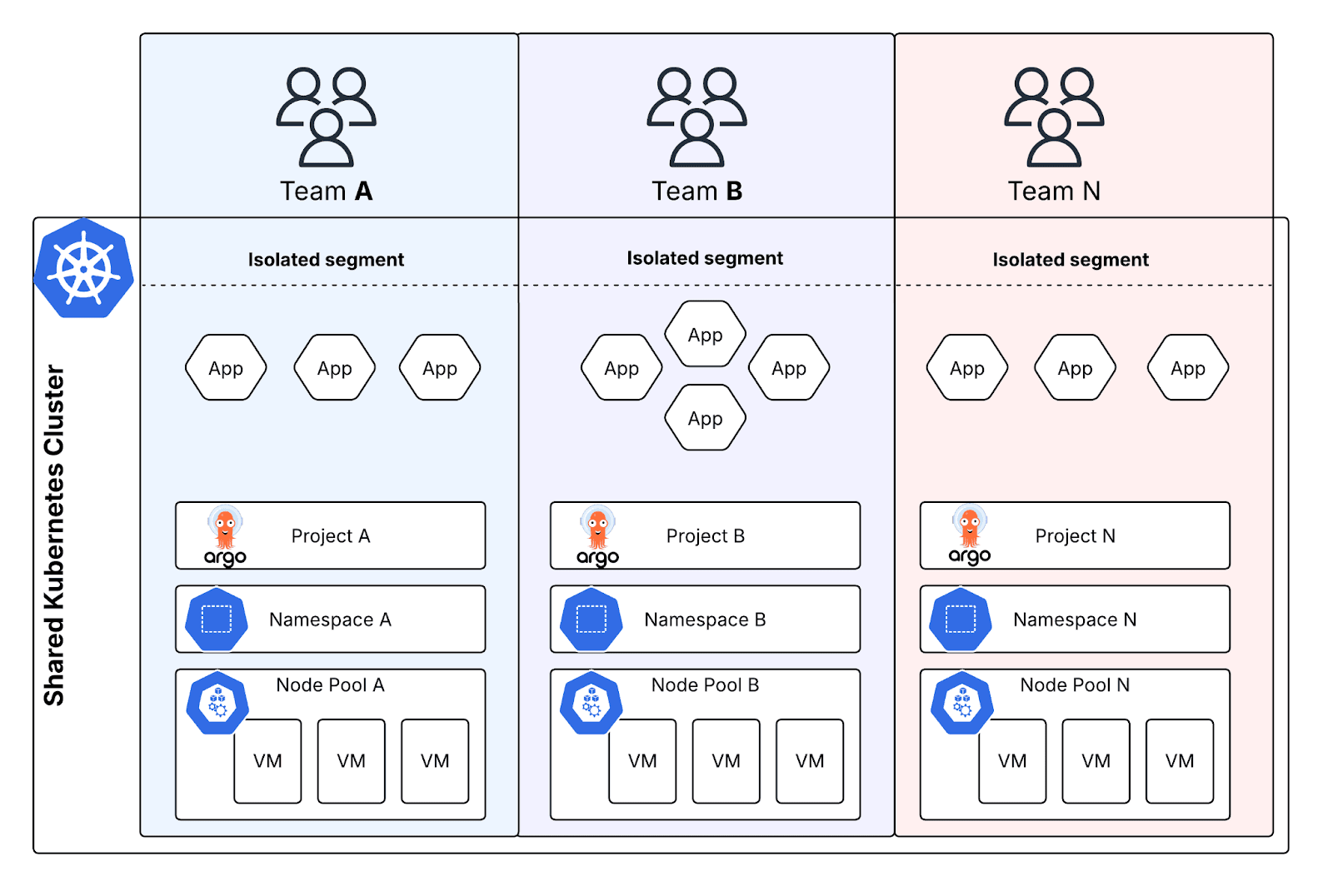
Layer 1: Namespace foundation
Start with proper namespace setup. Not just kubectl create namespace team-alpha, but namespaces that have opinions about resource usage:
apiVersion: v1
kind: Namespace
metadata:
name: team-alpha
labels:
team: alpha
environment: production
---
apiVersion: v1
kind: ResourceQuota
metadata:
name: team-alpha-quota
namespace: team-alpha
spec:
hard:
requests.cpu: "50"
requests.memory: 100Gi
requests.nvidia.com/gpu: "4"
pods: "30"
The labels matter! OPA Gatekeeper uses them later to automatically schedule workloads to the right places. This eliminates the manual coordination that is guaranteed to break down as teams scale.
Layer 2: Karpenter node pools
Here's where things get interesting. Instead of everyone fighting over the same pool of nodes, we give each team their own dedicated compute resources: This prevents the "noisy neighbor" problem at the infrastructure level:
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: team-alpha-pool
spec:
template:
metadata:
labels:
team: alpha
spec:
taints:
- key: team
value: alpha
effect: NoSchedule
nodeClassRef:
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
name: team-alpha-nodeclass
That NoSchedule taint is doing the heavy lifting here. It ensures only team-alpha pods can land here. The Assign mutations in Gatekeeper will automatically ensure pods get the right tolerations and nodeSelector values. This prevents the classic "why is my ML job running on a t2.micro" problem I've seen countless times.
Layer 3: OPA Gatekeeper to assign mutations
Manual processes don't scale. Instead of trusting developers to remember to add the right nodeSelectors and tolerations (they won't), Gatekeeper just does it automatically. This ensures pods land on the right nodes, regardless of what developers specify:
# Assign nodeSelector for team nodepool targeting
apiVersion: mutations.gatekeeper.sh/v1
kind: Assign
metadata:
name: nodepool-selector-team-alpha
spec:
applyTo:
- groups: [""]
kinds: ["Pod"]
versions: ["v1"]
location: "spec.nodeSelector"
match:
scope: Namespaced
kinds:
- apiGroups: [""]
kinds: ["Pod"]
namespaces: ["team-alpha"]
parameters:
assign:
value:
"karpenter.sh/nodepool": "team-alpha-pool"
"team": "alpha"
---
# Assign toleration for team nodepool
apiVersion: mutations.gatekeeper.sh/v1
kind: Assign
metadata:
name: nodepool-toleration-team-alpha
spec:
applyTo:
- groups: [""]
kinds: ["Pod"]
versions: ["v1"]
location: "spec.tolerations"
match:
scope: Namespaced
kinds:
- apiGroups: [""]
kinds: ["Pod"]
namespaces: ["team-alpha"]
parameters:
assign:
value:
- key: "team"
value: "alpha"
effect: "NoSchedule"
This automatic enforcement is crucial. The Assign mutations overwrite any existing nodeSelector or tolerations. Even if someone tries to schedule their pod on another team's resources, Gatekeeper forces the pod to the correct team infrastructure. No manual coordination required.
Layer 4: ArgoCD team projects to keep everyone honest
Finally, GitOps with ArgoCD makes sure deployments stay predictable and gives you that audit trail when things inevitably go sideways: each team gets their own ArgoCD project with strict namespace restrictions:
apiVersion: argoproj.io/v1alpha1
kind: AppProject
metadata:
name: team-alpha-project
namespace: argocd
spec:
description: "Team Alpha's isolated deployment project"
destinations:
- namespace: team-alpha
server: https://kubernetes.default.svc
sourceRepos:
- 'https://github.com/company/team-alpha-manifests'
roles:
- name: team-alpha
description: "Team Alpha deployment permissions"
policies:
- p, proj:team-alpha-project:team-alpha, applications, *, team-alpha-project/*, allow
- p, proj:team-alpha-project:team-alpha, applications, create, team-alpha-project/*, allow
- p, proj:team-alpha-project:team-alpha, applications, sync, team-alpha-project/*, allow
groups:
- team-alpha
---
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: team-alpha-services
namespace: argocd
spec:
project: team-alpha-project
source:
repoURL: https://github.com/company/team-alpha-manifests
path: services
targetRevision: HEAD
destination:
server: https://kubernetes.default.svc
namespace: team-alpha
syncPolicy:
automated:
prune: true
selfHeal: true
The key here is the destinations field. ArgoCD will reject any deployment attempt outside of the team's designated namespace. This prevents teams from accidentally (or intentionally) deploying to other team namespaces.
How it works in practice
Here’s what happens when a developer in team-alpha pushes a deployment:
- ArgoCD validates the deployment is targeting the correct namespace (team-alpha only), then applies the manifest
- Gatekeeper intercepts the pod creation and assigns the correct nodeSelector and tolerations for team-alpha
- Karpenter sees the scheduling request and provisions a node from the team-alpha pool if needed
- The pod lands on a dedicated node with Namespace quotas preventing resource exhaustion
If team-beta tries to deploy to team-alpha's namespace, ArgoCD blocks it entirely.
Real-World Results
After implementing this stack, we saw immediate improvements in both team velocity and SRE effectiveness:
- Deployment velocity increased — teams no longer wait for SRE approval for routine changes
- SRE ticket volume decreased — automated policy enforcement prevents most configuration issues
- Time to onboard new teams reduced from weeks to hours — standardized isolation patterns eliminate custom setup
- Zero cross-team resource conflicts since implementation — automated boundaries work better than manual coordination
Most importantly, teams now view SRE as enablers rather than gatekeepers. We focus on platform improvements and complex problem-solving instead of routine deployment approvals.
A cherry on the cake: Helm templates for zero-touch onboarding
To make team self-service truly scalable, we created a Helm chart that generates all team resources with a single command:
# example values.yaml
team:
name: "team-alpha"
resourceQuota:
cpu: "50"
memory: "100Gi"
nodepool:
instanceTypes: ["m5.large", "m5.xlarge"]
spotEnabled: true
argocd:
repoUrl: "https://github.com/company/team-alpha-manifests"
sourcePath: "services"
Now onboarding a new team is literally one command:
helm install team-beta ./team-isolation-chart \
--set team.name=team-beta \
--set team.argocd.repoUrl=https://github.com/company/team-beta-manifests
Boom! This one command creates the namespace, quotas, Karpenter nodepool, Gatekeeper assignments, and ArgoCD project. Teams get immediate access to self-service deployment capabilities with all isolation guardrails automatically configured.
The bottom line
The goal of SRE isn't to manually prevent every possible failure. It's to build systems that prevent failures automatically while enabling team autonomy.
This four-layer approach transforms SRE from a deployment bottleneck into a platform enabler. Teams get the independence they need to move fast, while automated guardrails prevent the resource conflicts and scheduling disasters that manual processes were designed to catch.
Each tool does what it's actually good at: Namespaces handle logical separation, Karpenter manages compute resources automatically, Gatekeeper enforces policies without human intervention, and ArgoCD enables safe self-service deployments. Together, they create strong isolation without requiring constant SRE oversight.
Your teams stay productive, your SRE team focuses on high-value platform work, and everyone sleeps better knowing that automated systems are preventing the disasters that used to require manual coordination.

Rein Remmel
CEO
20+ years of experience building highly performing teams and mission critical information systems for government, startups and global enterprises.
Rein has worked as software engineer, infrastructure architect, team lead and for last 10+ years as CEO of Entigo.
Stay updated on future stories

READ MORE

DEVOPS
How Crossplane compositions turned infrastructure tickets into self-service APIs

IAC
From tech stack to business value: platform engineering & Kubernetes
DEVOPS
Team isolation in Kubernetes: the four-layer stack that actually works

IAC
Mitigating Docker Hub rate limitations and Crossplane package restrictions with registry proxies






info@entigo.com | (+372) 600 6130 | Veerenni 40a, Tallinn, 10138